📖 Introduction
We introduce LoongX, which effectively integrates multimodal neural signals from datasets L-Mind to guide image editing through Cross-Scale State Space (CS3) encoder and Dynamic Gated Fusion (DGF) modules. Experimental results demonstrate that editing performance using only multimodal neural signals is comparable to text-driven baselines (CLIP-I: 0.6605 vs. 0.6558), and the combination of neural signals with speech instructions surpasses text prompts alone (CLIP-T: 0.2588 vs. 0.2549), proving the method's effectiveness and its significant potential in intuitive and inclusive human-AI interaction.
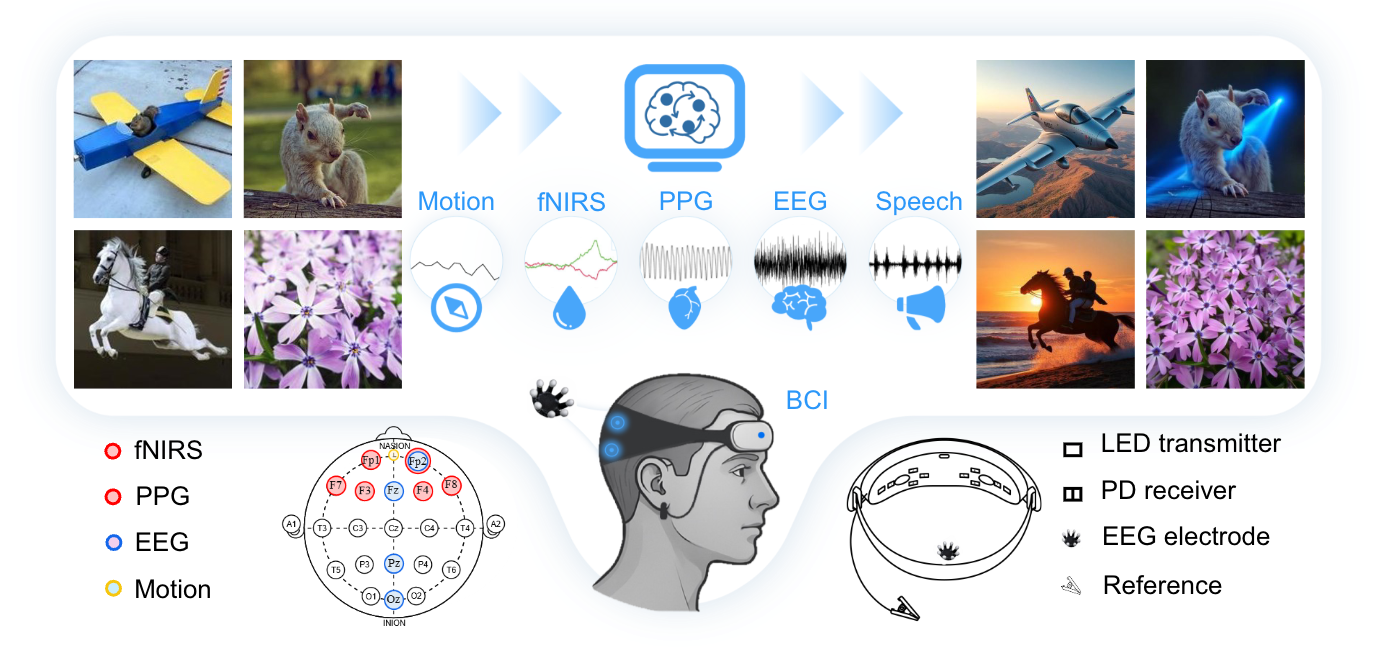
LoongX leverages multimodal neural signals from advanced brain-computer interfaces (BCIs) to enable hands-free image editing, driven solely by your thoughts!